Keywords: Text2Motion, VQ-VQE, Resnet, Transformer, 2024
MoMask: Generative Masked Modeling of 3D Human Motions_CVPR_2024
Chuan Guo∗ Yuxuan Mu∗ Muhammad Gohar Javed∗ Sen Wang
Li Cheng
University of Alberta
{cguo2, ymu3, javed4, lcheng5}@ualberta.ca
Web:
https://ericguo5513.github.io/momask/

WorkFlow
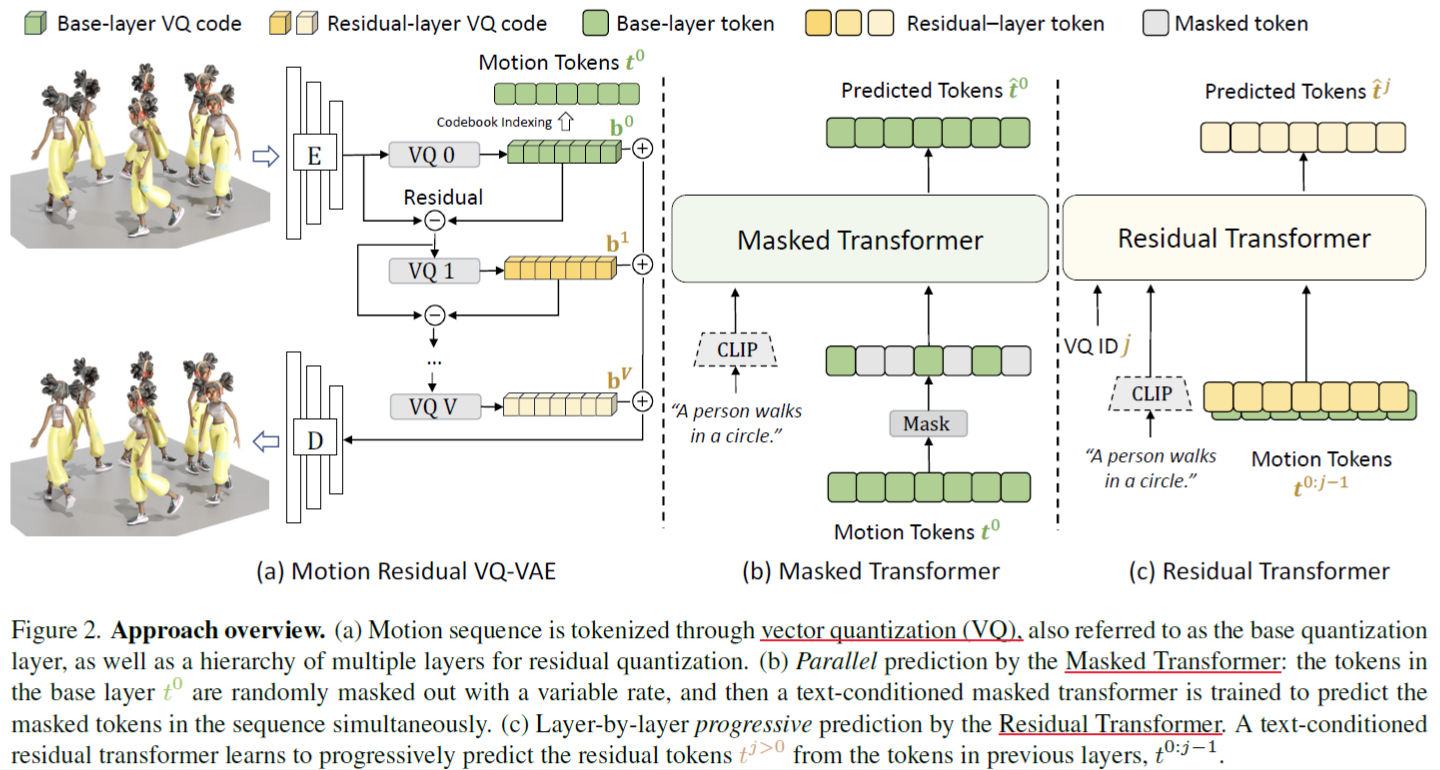
Inspiration
Conventional motion VQ-VAEs [16, 21, 49, 52] transform a motion sequence into one tuple of discrete motion tokens. inevitably leads to information loss, which further limits the quality of reconstruction.
Methods
Our main contributions can be summarized as follows:
First, our MoMask is the first generative masked modeling framework for the problem of text-to-motion generation. It comprises of a hierarchical quantization generative model and the dedicated mechanism for precise residual quantization, base token generation and residual token prediction.
Second, our MoMask pipeline produces precise and efficient text-to-motion generation. Empirically, it achieves new state-of-the-art performance on text-to-motion generation task with an FID of 0.045 (vs. 0.141 in [49]) on HumanML3D and 0.204 (vs. 0.514 in [49]) on KIT-ML.
Third, our MoMask also works well for related tasks, such as textguided motion inpainting.
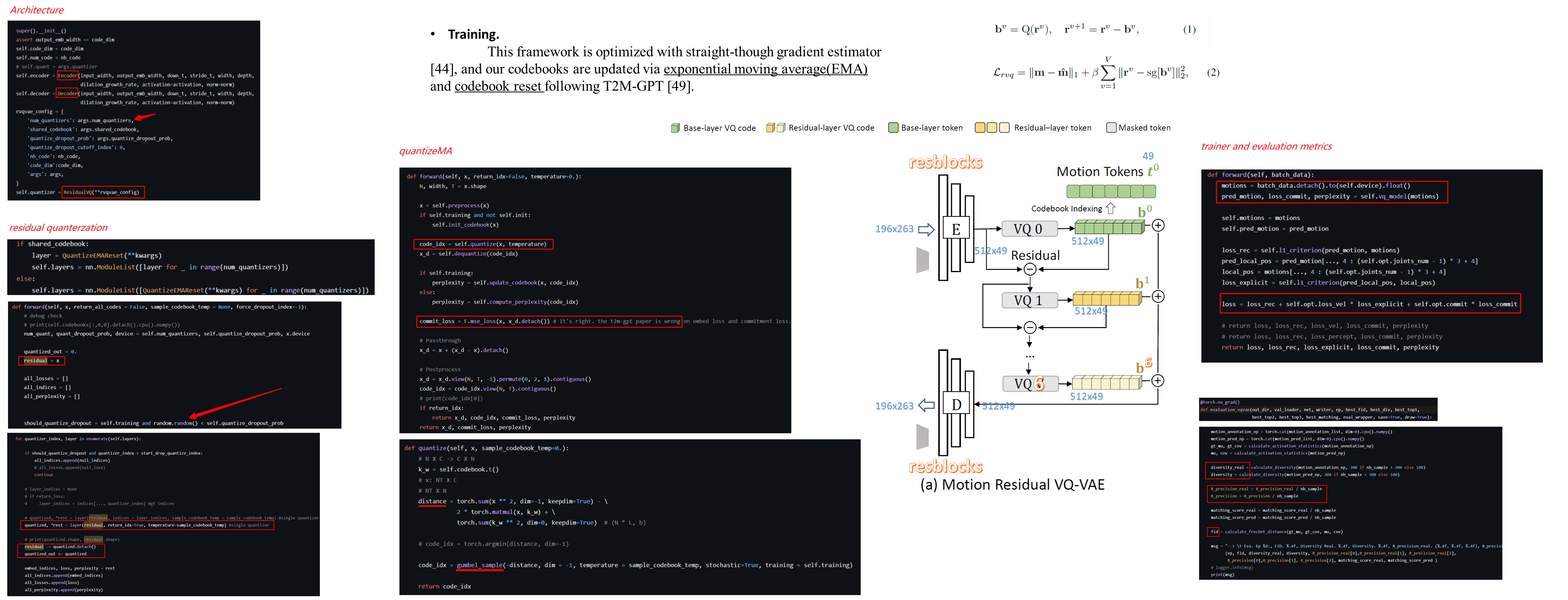
RVQ-VQE
borrowed from this paper:
https://arxiv.org/pdf/2107.03312.pdf
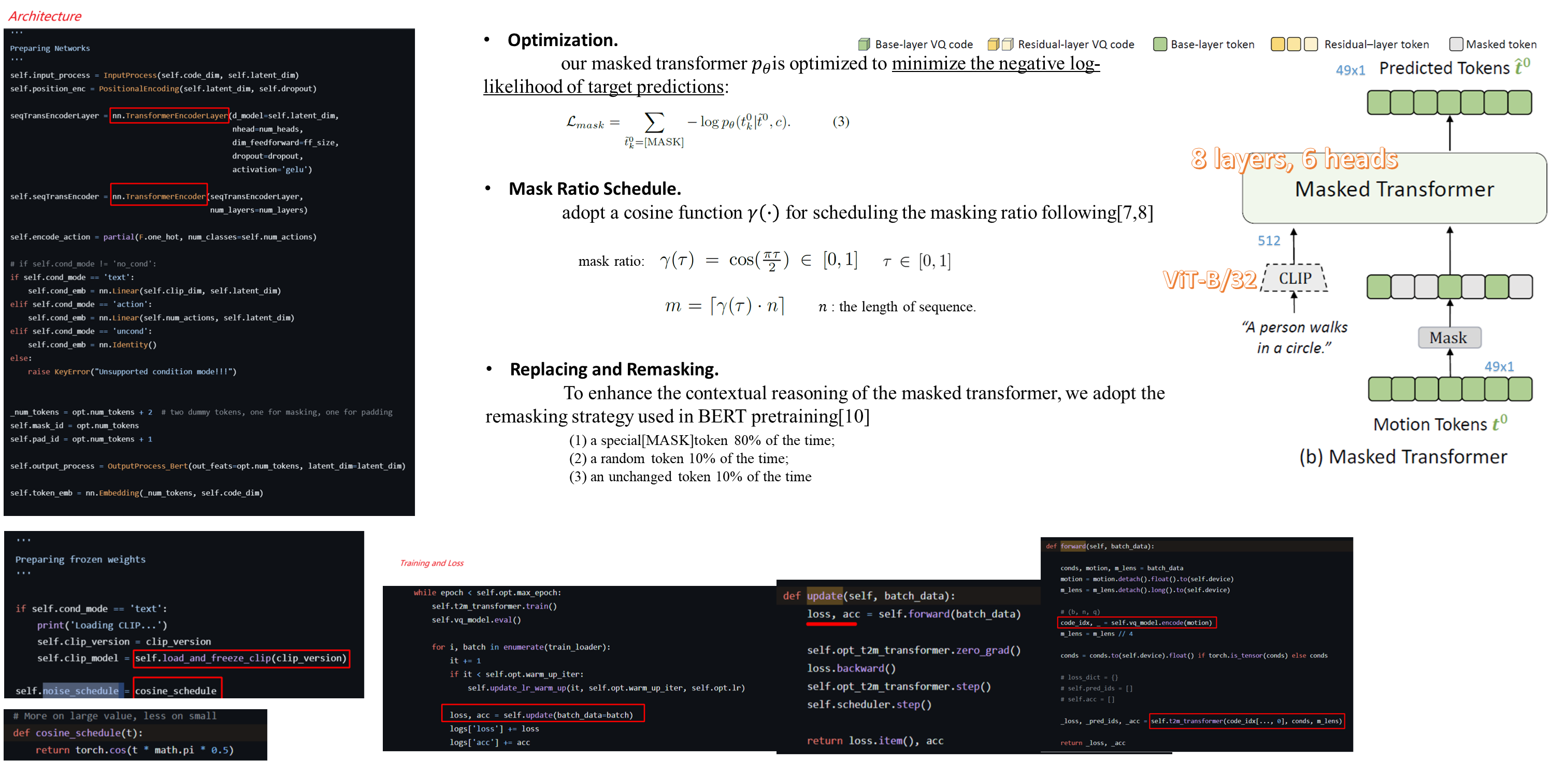
Masked-Transformer
Residual-Transformer

Comparision

Limitation
Firstly, while MoMask excels in fidelity and faithfulness for text-to-motion synthesis, its diversity is relatively limited.
Secondly, MoMask requires the target length as input for motion generation. This could be properly addressed by applying the text2length sampling [15] beforehand.
Thirdly, akin to most VQ-based methods, MoMask may face challenges when generating motions with fast-changing root motions, such as spinning.
Reference
x[9] Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18000–18010, 2023.
x[15] Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5152–5161, 2022.
x[16] Chuan Guo, Xinxin Zuo, Sen Wang, and Li Cheng. Tm2t: Stochastic and tokenized modeling for the reciprocal generation of 3d human motions and texts. In European Conference on Computer Vision, pages 580–597. Springer, 2022
[21] Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign language. arXiv preprint arXiv:2306 14795, 2023.
[23] Hanyang Kong, Kehong Gong, Dongze Lian, Michael Bi Mi, and Xinchao Wang. Priority-centric human motion generation in discrete latent space. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14806–14816, 2023.
x[42] Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion diffusion model. arXiv preprint arXiv:2209.14916, 2022.
x[49] Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Shaoli Huang, Yong Zhang, Hongwei Zhao, Hongtao Lu, and Xi Shen. T2m-gpt: Generating human motion from textual descriptions with discrete representations. arXiv preprint arXiv:2301.06052, 2023.
[52] Yaqi Zhang, Di Huang, Bin Liu, Shixiang Tang, Yan Lu, Lu Chen, Lei Bai, Qi Chu, Nenghai Yu, andWanli Ouyang. Motiongpt: Finetuned llms are general-purpose motion generators. arXiv preprint arXiv:2306.10900, 2023.
x[50] Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Motiondiffuse: Text-driven human motion generation with diffusion model. arXiv preprint arXiv:2208.15001, 2022.
x[51] Mingyuan Zhang, Xinying Guo, Liang Pan, Zhongang Cai, Fangzhou Hong, Huirong Li, Lei Yang, and Ziwei Liu. Remodiffuse: Retrieval-augmented motion diffusion model. arXiv preprint arXiv:2304.01116, 2023.

