Keywords: Children’s Drawing, Existing Models and Techniques, Mask R-CNN,
A Method for Animating Children’s Drawings of the Human Figure_ACM Transactions on Graphics_2023
HARRISON JESSE SMITH , Meta AI Research, USA
QINGYUAN ZHENG , Tencent America, USA
YIFEI LI , MIT CSAIL, USA
SOMYA JAIN , Meta AI Research, USA
JESSICA K. HODGINS , Carnegie Mellon University, USA
Authors’ addresses:
H. J. Smith and S. Jain, Meta AI, 1 Hacker Way, Menlo Park, CA 94025 USA; emails: {hjessmith, somyaj}@gmail.com;
Q. Zheng, Tencent America, 2747 Park Blvd, Palo Alto, CA 94306 USA; email: qyzzheng@global.tencent.com;
Y. Li, MIT CSAIL, 32 Vassar St, Cambridge, MA 02139 USA; email: liyifei@csail.mit.edu;
J. K. Hodgins, Carnegie Mellon University, 5000 Forbes Ave, Pittsburgh, PA 15213 USA; email: jkh@cmu.edu.
https://sketch.metademolab.com/

WorkFlow
Problem
Who among us has not wished, either as a child or as an adult, to see such figures come to life and move around on the page? Sadly, while it is relatively fast to produce a single drawing, creating the sequence of images necessary for animation is a much more tedious endeavor, requiring discipline, skill, patience, and sometimes complicated software. As a result, most of these figures remain static upon the page.
Innovation
Inspired by the importance and appeal of the drawn human figure, we design and build a system to automatically animate it given an in-the-wild photograph of a child’s drawing.
While our system leverages existing models and techniques, most are not directly applicable to the task due to the many differences between photographic images and simple pen-and- paper representations.
To summarize, our contributions are as follows:
We explore the problem of automatic sketch-to-animation for children’s drawings of human figures and present a framework that achieves this effect.
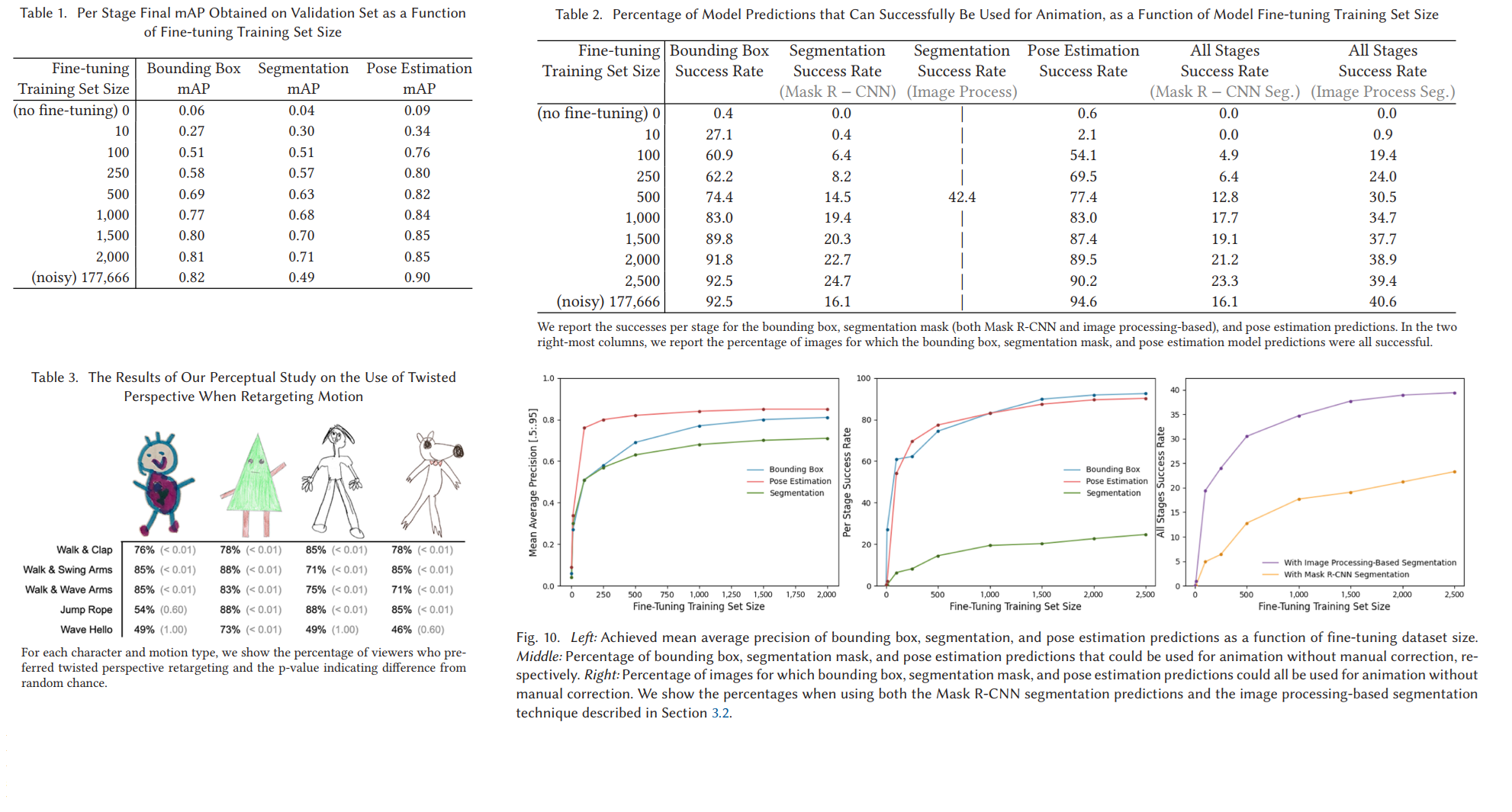
We also present a set of experiments determining the amount of training data necessary to achieve high levels of success and a perceptual study validating the usefulness of our motion retargeting technique.To encourage additional research in the domain of amateur drawings, we present a first-of-its-kind dataset of 178,166 user-submitted amateur drawings, along with user accepted bounding box, segmentation mask, and joint location annotations.
Our work builds on existing methods from several fields but is, to our knowledge, the first work focused specifically on fully automatic animation of children’s drawings of human figures.
Methods
In Machine Learning, in-the-wild means 数据源的多样性比较高,包含的场景多,可以用来间接证明模型的泛化能力比较强
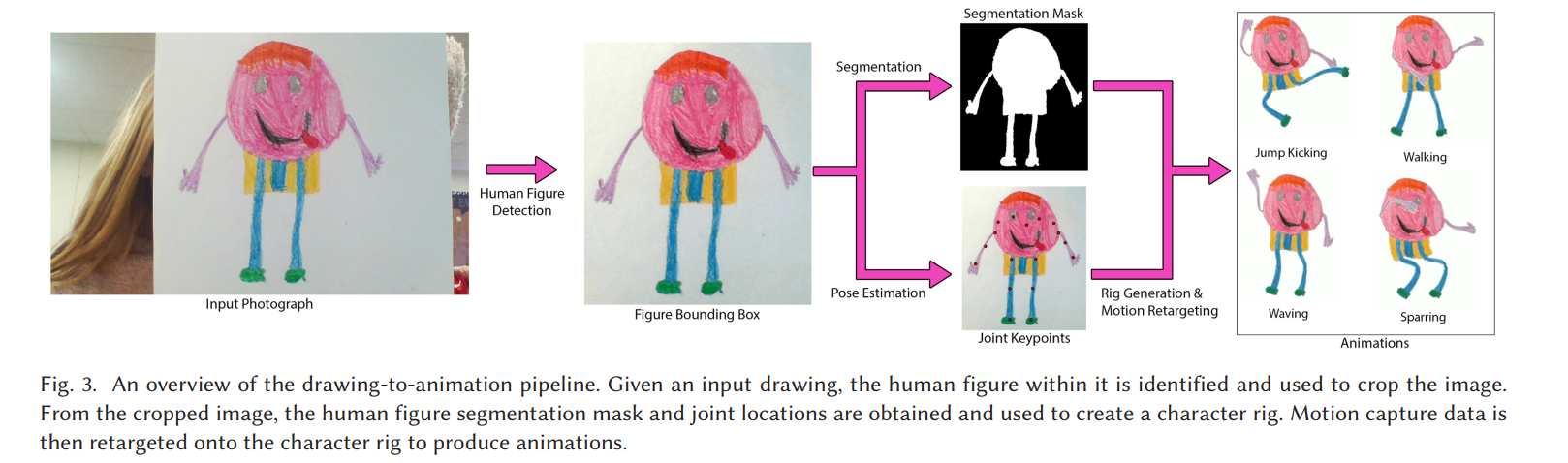
Figure Detection
We make use of a state-of-the-art object detection model, Mask R-CNN [He et al. 2017], with a ResNet-50+FPN backbone.

Therefore, we fine-tune the model.
The model’s backbone weights are frozen and attached to a head, which predicts a single class, human figure. The weights of the head are then optimized using cross-entropy loss and stochastic gradient descent with an initial learning rate of 0.02, momentum of 0.9, weight decay of 1e-4, and minibatches of size 8. Training was conducted using OpenMMLab Detection Toolbox [Chen et al. 2019]; all other hyperparameters were kept at the default values provided by the toolbox.
Figure Segmentation

traditional contour detection algorithms / 形态学 轮廓 边界跟踪 算法
First, we resize the bounding box-cropped image to a width of 400 pixels while preserving the aspect ratio.
Next, we convert the image to grayscale and perform adaptive thresholding, where the threshold value is a Gaussian-weighted sum of the neighborhood pixel values minus a constant C [Gonzalez and Woods 2008].Here, we use a distance of 8 pixels to define the neighborhood and a value of 115 for $C$.
高斯核模糊:平滑最终提取的轮廓, Gaussian kernel blur: Smooths the final extracted contour
To remove noise and connect foreground pixels, we next perform morphological closing, followed by dilating(扩张), using 3×3 rectangular kernels.
扩张可以防止提取到的轮廓过于贴合从而丢失完整性, Dilation prevents the extracted contours from fitting too well and losing completeness
We then flood fill from the edges of the image, ensuring that any closed groups of foreground pixels are solid and do not contain holes. (BFS)
Finally, we calculate the area of each distinct foreground polygon and retain only the one with the largest area.
OpenCV has Mature algorithms
However, it will fail when body parts are drawn separated, limbs are drawn touching at points other than the joints, the figure is not fully contained by the bounding box, or the outline of the figure is not completely connected.
Pose Estimation

We assume the presence of the 17 keypoints used by MS-COCO [Lin et al. 2014](see Figure 8 ) and use a pose estimation model to predict their locations.
We therefore train a custom pose estimation model utilizing a ResNet-50 backbone, pretrained on ImageNet, and a top-down heat map keypoint head that predicts an individual heatmap for each joint location.
The cropped human figure bounding box is resized to 192×256 and fed into the model, and the highest-valuedpixel in each heatmap is taken as the predicted joint location.
Mean squared error is used for joint loss, and optimization is performed using Adaptive Momentum Estimation with learning rate of 5e-4 and minibatches of size 512. Training was conducted using the OpenMMLab Pose Toolbox [Contributors 2020]; all other hyperparameters were kept at the default values provided by this toolbox.
Animation
From the segmentation mask, we use Delaunay triangulation to generate a 2D mesh.
Using the joint locations, we construct a character skeleton.
We average the position of the two hips to obtain a root joint and average the position of the two shoulders to obtain the chest joint. We connect these joints to create the skeletal rig as shown in Figure 8 (b).
Finally, we assign each mesh triangle to one of nine different body part groups (left upper leg, left lower leg, right up- per leg, right lower leg, left upper arm, left lower arm, right upper arm, right lower arm, and trunk) by finding the closest bone to each triangle’s centroid.
We animate the character rig by translating the joints and using as-rigid-as-possible (ARAP) shape manipulation[Igarashi et al. 2005] to repose the character mesh.
To make the process simple for the user, we drive the character rig using a library of preselected motion clips obtained from human performers.
We retarget the motion in the following manner:
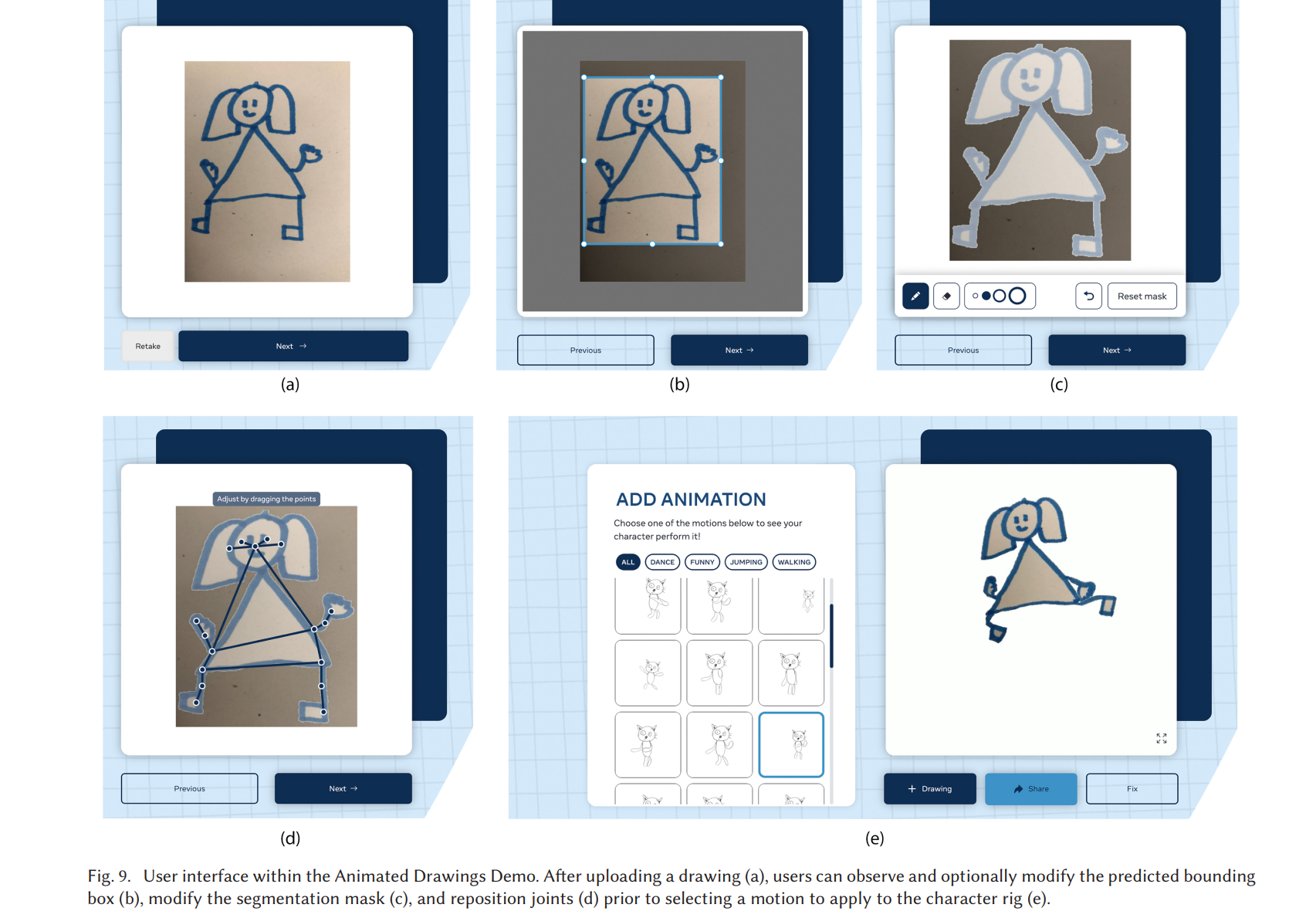
Fine-Tune
Related Work
2D Image to Animation
Hornung et al. present a method to animate a 2D character in a photograph, given user-annotated joint locations [Hornung et al. 2007].
👉Alexander Hornung, Ellen Dekkers, and Leif Kobbelt. 2007. Character animation from 2D pictures and 3D motion data. ACM Trans. Graph. 26, 1 (Jan. 2007), 1–es. DOI: https://doi.org/10.1145/1189762.1189763Pan and Zhang demonstrate a method to animate 2D characters with user-annotated joint locations via a variable-length needle model [Pan and Zhang 2011].
👉Junjun Pan and Jian J. Zhang. 2011. Sketch-based Skeleton-driven 2D Animation and Motion Capture . Springer Berlin, 164–181. DOI: https://doi.org/10.1007/978- 3- 642- 22639-7 _ 17Jain et al. present an integrated approach to generate 3D proxies for animation given joint locations, segmentation masks, and per-part bounding boxes [Jain et al. 2012].
👉Eakta Jain, Yaser Sheikh, Moshe Mahler, and Jessica Hodgins. 2012. Three- dimensional proxies for hand-drawn characters. ACM Trans. Graph. 31, 1 (Feb. 2012).
Levi and Gotsman provide a method to create an artic- ulated 3D object from a set of annotated 2D images and an initial 3D skeletal pose [Levi and Gotsman 2013].
👉Zohar Levi and Craig Gotsman. 2013. ArtiSketch: A system for articulated sketch modeling. Comput. Graph. Forum 32, 2pt2 (2013), 235–244. DOI: https://doi.org/ 10.1111/cgf.12043Live Sketch [Su et al. 2018] tracks control points from a video and applies their motion to user-specified control points upon a character.
👉Qingkun Su, Xue Bai, Hongbo Fu, Chiew-Lan Tai, and Jue Wang. 2018. Live sketch: Video-driven dynamic deformation of static drawings. In Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI’18) . Association for Computing Machinery, New York, NY, 1–12. DOI: https://doi.org/10.1145/ 3173574.3174236Other approaches allow the user to specify character motions through a puppeteer interface, using RGB or RGB-D cameras [Barnes et al. 2008 ; Held et al. 2012].
👉Robert Held, Ankit Gupta, Brian Curless, and Maneesh Agrawala. 2012. 3D puppetry: A Kinect-based interface for 3D animation. In Proceedings of the 25th Annual ACM Symposium on User Interface Software and Technology (UIST’12) . Associa- tion for Computing Machinery, New York, NY, 423–434. DOI: https://doi.org/10. 1145/2380116.2380170
ToonCap [Fan et al. 2018] focuses on an inverse problem, capturing poses of a known cartoon character, given a previous image of the character annotated with layers, joints, and handles.
👉Xinyi Fan, Amit H. Bermano, Vladimir G. Kim, Jovan Popović, and Szymon Rusinkiewicz. 2018. ToonCap: A layered deformable model for capturing poses from cartoon characters. In Proceedings of the Joint Symposium on Computational Aesthetics and Sketch-Based Interfaces and Modeling and Non-photorealistic Animation and Rendering (Expressive’18) . Association for Computing Machinery, New York, NY. DOI: https://doi.org/10.1145/3229147.3229149ToonSynth [Dvorožnák et al. 2018 ] and Neural Puppet [Poursaeed et al. 2020] both present methods to synthesize animations of hand-drawn characters given a small set of drawings of the character in specified poses.
👉Marek Dvorožnák, Wilmot Li, Vladimir G. Kim, and Daniel Sýkora. 2018. ToonSynth: Example-based synthesis of hand-colored cartoon animations. ACM Trans. Graph. 37, 4 (July 2018). DOI: https://doi.org/10.1145/3197517.3201326
👉Omid Poursaeed, Vladimir Kim, Eli Shechtman, Jun Saito, and Serge Belongie. 2020. Neural puppet: Generative layered cartoon characters. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision . 3346–3356.Hinz et al. train a network to generate new animation frames of a single character given 8–15 training images with user-specified keypoint annotations [Hinz et al. 2022].
👉Tobias Hinz, Matthew Fisher, Oliver Wang, Eli Shechtman, and Stefan Wermter. 2022. CharacterGAN: Few-shot keypoint character animation and reposing. In Pro- ceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . 1988–1997.
- Monster Mash [Dvorožňák et al. 2020] presents an intuitive framework for sketch-based modeling and animation.
👉Marek Dvorožňák, Daniel Sýkora, Cassidy Curtis, Brian Curless, Olga Sorkine- Hornung, and David Salesin. 2020. Monster mash: A single-view approach to ca- sual 3D modeling and animation. ACM Trans. Graph. 39, 6 (Nov. 2020). DOI: https: //doi.org/10.1145/3414685.3417805 .
- 2.5D Cartoon Models [Rivers et al. 2010] presents a novel method of con- structing 3D-like characters from a small number of 2D represen- tations.
👉Alec Rivers, Takeo Igarashi, and Frédo Durand. 2010. 2.5D cartoon models. ACM Trans. Graph. 29, 4 (July 2010). DOI: https://doi.org/10.1145/1778765.1778796
Some animation methods are specifically tailored toward par- ticular forms, such as faces [Averbuch-Elor et al. 2017], coloring- book characters [Magnenat et al. 2015], or characters with human- like proportions. One notable work that is focused on the human form is Photo Wake Up [Weng et al. 2019].
Detection, Segmentation, and Pose Estimation on Non-photorealistic Images
Some researchers are addressing this problem by devel- oping methods and releasing datasets focused on
the domain of anime characters [Chen and Zwicker 2022; Khungurn and Chou 2016]
👉Shuhong Chen and Matthias Zwicker. 2022. Transfer learning for pose estimation of illustrated characters. In Proceedings of the IEEE/CVF Winter Conference on Appli- cations of Computer Vision .professional sketches [Brodt and Bessmeltsev 2022]
👉Kirill Brodt and Mikhail Bessmeltsev. 2022. Sketch2Pose: Estimating a 3D character pose from a bitmap sketch. ACM Trans. Graph. 41, 4 (July 2022). DOI: https://doi. org/10.1145/3528223.3530106mouse doodles [Ha and Eck 2017].

