Keywords: Probability Distribution Model, Variational Inference, Normalizing Flow, 2022
Keyframe Control of Music-driven 3D Dance Generation_IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS_2022
• Z. Yang, S.-Y. Chen and L. Gao are with the Beijing Key Laboratory of Mobile Computing and Pervasive Device, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China, and also with the University of Chinese Academy of Sciences, Beijing 100190, China.
E-mail: yangzhipeng19s@ict.ac.cn, chenshuyu@ict.ac.cn, gaolin@ict.ac.cn
• Y.-H. Wen and Y.-J. Liu are with the CS Dept, BNRist, Tsinghua University,
Beijing 100190, China.
Email: wenyh1616@tsinghua.edu.cn, liuyongjin@tsinghua.edu.cn
• X. Liu and Y. Gao are with Tomorrow Advancing Life Education Group,
Beijing 100190, China.
Email: liuxiao15@tal.com, gaoyuan23@tal.com
• H. F is with the School of Creative Media, City University of Hong Kong.
Email: hongbofu@cityu.edu.hk
Video:
https://www.youtube.com/watch?v=eJ8mFzzZ0mk

WorkFlow
Problem
Most existing deep learning methods mainly rely on music for dance generation and lack sufficient control over generated dance motions.
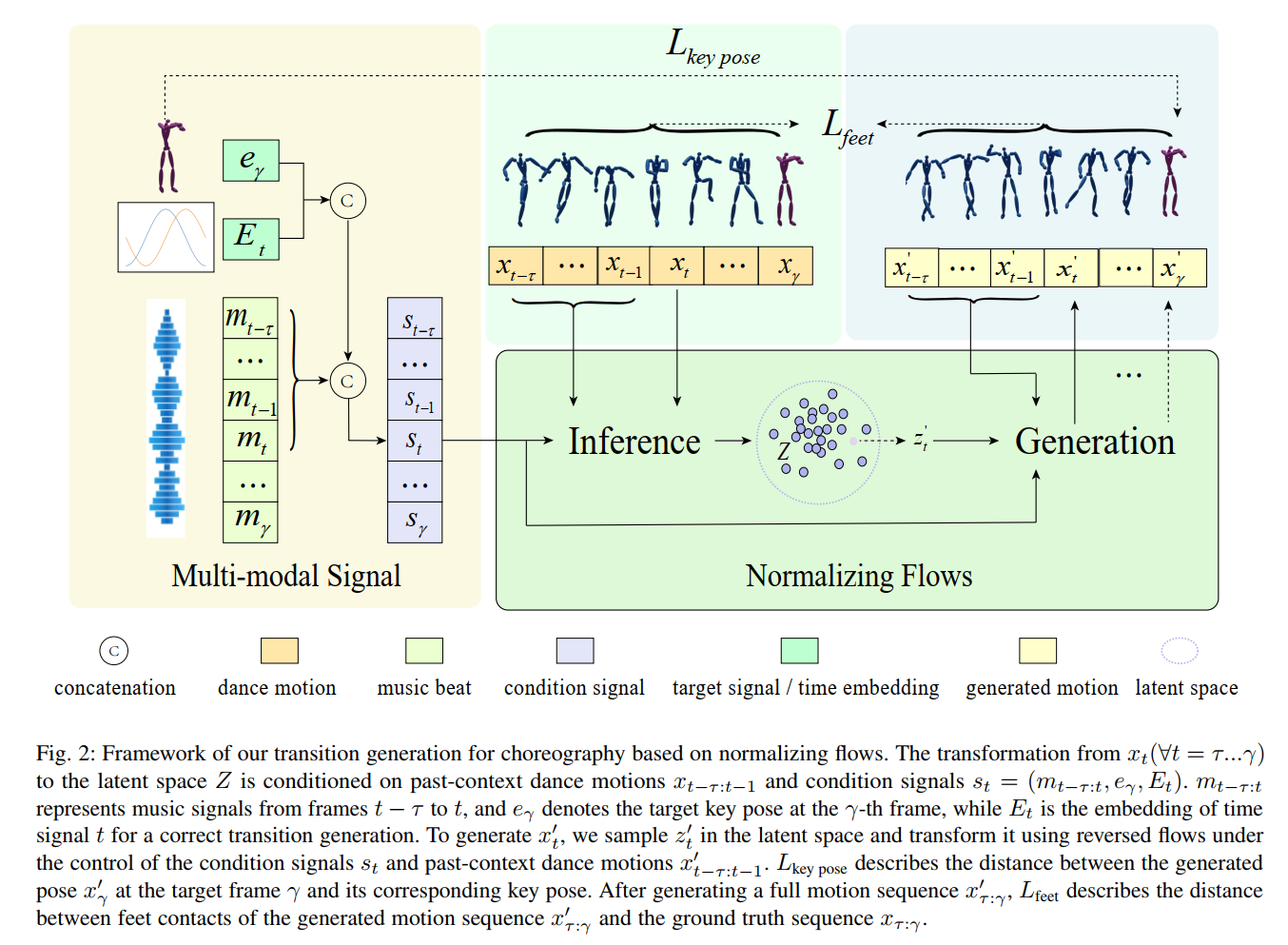
To address this issue, we introduce the idea of keyframe interpolation for music-driven dance generation and present a novel transition generation technique for choreography.
Inspiration
keyframe-based control, which allows artists to depict their ideas via a sparse set of keyframes, has been widely adopted for creating 2D and 3D animations. Inspired by this, we build a probabilistic model for dance generation conditioned on the input music and key poses.
the probabilistic model cannot generate transition dance motions between keyframes robustly, because the distance between a target pose and its corresponding generated pose is not clear and each generated dance motion is not aware of the number of left frames to its target keyframe due to the varying intervals between key poses. To solve this problem, we add a key pose loss term that describes the distance between the input key poses and their corresponding generated poses to our objective function for modeling the distribution of dance motions.
introduce a time embedding at each timestep as an additional condition to achieve a robust transition generation of varying lengths.
Methods
👉First Understand Variational Inference >>
👉Second Understand Variational Inference with Normalizing Flow >>
Losses
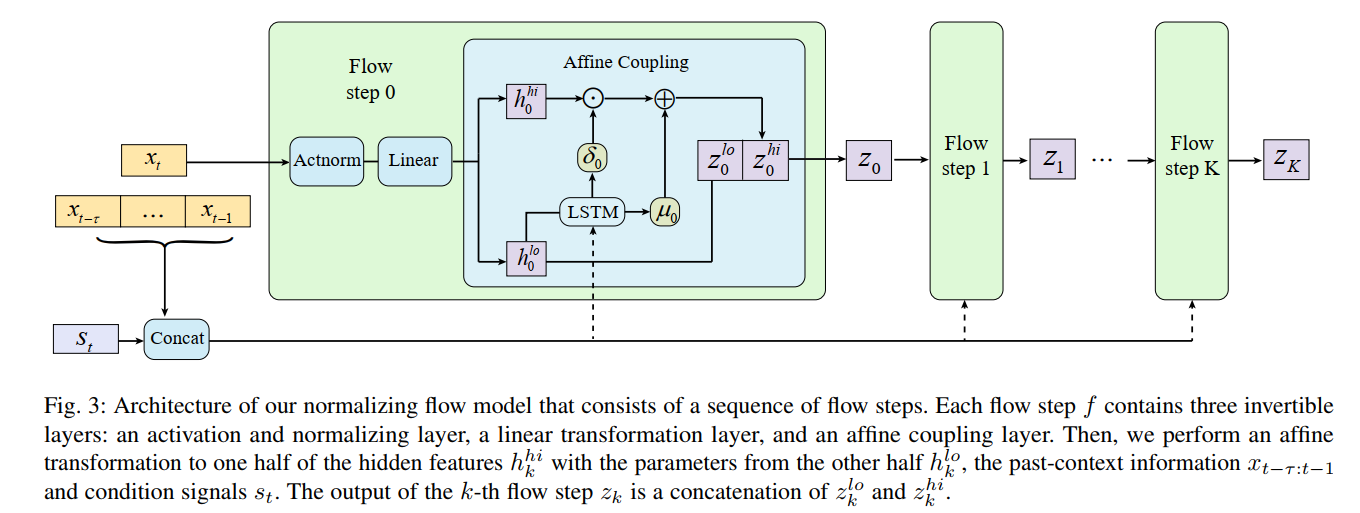
$$
\mathcal{L}_{flows} = \log q(z_K | x_{t-\tau : t}, s_t)
= - \sum_{d=1}^{D} (\frac{1}{2}\epsilon^2_d + \frac{1}{2}\log(2\pi) + \sum_{k=0}^K \log \delta_{k,d})
$$
calculate the key pose loss for the generated sequence with an $L_2$ norm, where Forward Kinematics (FK) is performed to calculate the global joint positions of the human motion.
$$
\mathcal{L}_{key-pose} = ||FK(x_\gamma’) - FK(e_\gamma)||_2
$$
use a contact-based loss constrain the distance between the generated feet contacts $c_t’$ of $x_t’$ and ground-truth contacts $c_t$ of $x_t$,
$$
\mathcal{L}_{feet} = \frac{1}{\gamma - \tau} \sum_{t = \tau}^{\gamma} ||c_t’ - c_t||_1
$$
$$
\mathcal{L}_{total} = \omega_1 \mathcal{L}_{flows} + \omega_2\mathcal{L}_{key-pose} + \omega_3 \mathcal{L}_{feet}
$$
Time Embedding
use positional encodings, which shift smoothly and uniquely to represent the location of each frame
$$
E_{t,2l} = \sin(\frac{nt}{basis^{2l/D}})
$$
$$
E_{t,2l+1} = \cos(\frac{nt}{basis^{2l/D}})
$$
where $nt$ is the time step between the start frame and the target frame. $nt$ can evolve forward and backward in time.
it is better to use $nt$ evolving backward, which represents the number of frames left to reach the target frame.
$D$ denotes the dimension of the input motion, and $l \in [0, \cdots, D/2]$.
Comparision
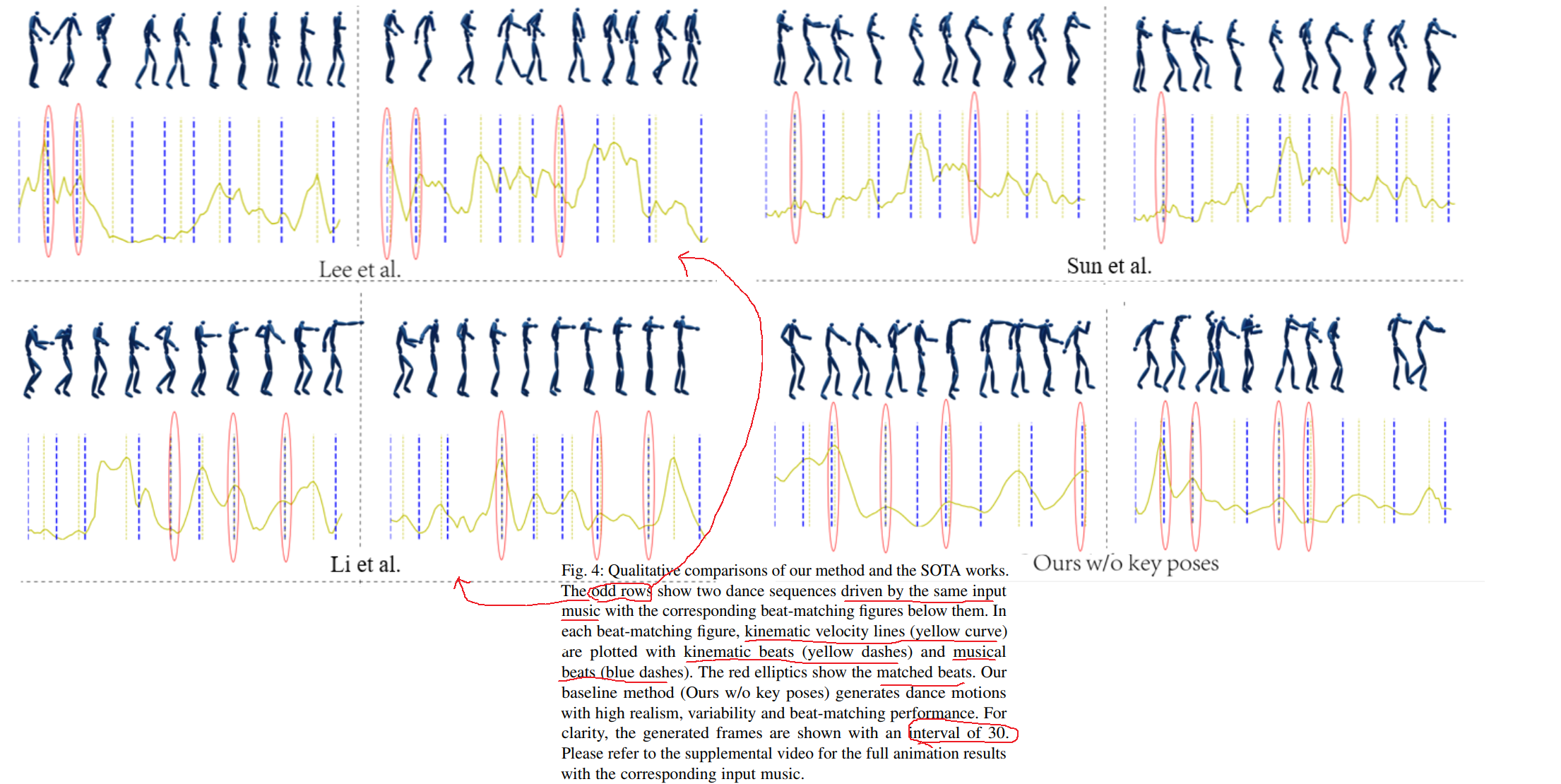
- our method is more realistic, generate more movements.
- our method outperforms the other methods in beat alignment.
- our method generates more variable dance motions given the same music clip.
- out method generates diverse results given different music inputs while other methods generate similar motions.

Limitation
- our method cannot generate dance styles not covered in the training dataset. This might be improved by expanding the datasets with additional styles, like Classical, Jazz, etc.
- the generated poses in key frames might still have small differences compared to the given key poses. The gaps particularly exist in rotation angles of end effectors (feet and hands). This issue might addressed by a further refinement in the feet and hand details.
Future Research
- developing an interactive dance composing system, where users can easily input desired music pieces and target poses to drive automatic dance generation.
- the target poses can be chosen from a database or reconstructed from user-specified human dancing photos by a reconstruction function integrated in the system.
- synthesizing dance motions conditioned on human emotion is another interesting research direction.

